Anomaly Detection
아래 내용은 고려대학교 강필성 교수님의 강의를 바탕으로 정리했습니다.
Anomaly Detection
- abnormal / novel data / outliers 란?
- 다른 관찰들과 비교해 생성방식이 다른 매커니즘을 따르는 관찰
- 데이터의 발생 메커니즘이 이미 정해진 상황에서 생성방식이 다른 데이터를 찾아내는법
- 데이터 밀도가 낮은 데이터
- 데이터 발생 메커니즘이 반드시 같을 필요는 없으며 그 발생빈도가 낮은 데이터를 찾아내는 방법
- 일반적으로 abnormal, outliers는 부정적 / novel data 는 긍정적인 의미를 내포하며 outliers 는 단변량, abnormal은 다변량에 대한 이상치를 의미합니다.
- 다른 관찰들과 비교해 생성방식이 다른 매커니즘을 따르는 관찰
- Noise data vs. Outliers
- 노이즈는 데이터를 수집하는 과정에서 자연/필연적으로 발생하는 데이터로 처리과정에서 안고가야하는 변수입니다.
Classification vs. Anomaly Detection
- 이상 데이터를 감지하기 위해서 보통 2가지 방법을 사용하게 됩니다.

- Classification은 양질/불량 데이터를 모두 학습시켜 단순히 분류를 하는 방법으로 작동합니다.
- 반면에 Anomaly detection은 정상 데이터만을 학습시키며 테스트 데이터가 학습에 사용한 데이터와 일관성이 있는지 등을 확인하여 불량 데이터 여부를 판단합니다.
- 그래서 Anomaly detection은 generalization / specialization 이라는 2가지의 상반된 능력을 가지게 되며 이를 적절히 조율하는 것이 모델의 성능을 높일 수 있는 방법입니다.
- 두 가지 방법 중 어떤 모델을 선택할 지는 데이터의 양을 기준으로 판단합니다.
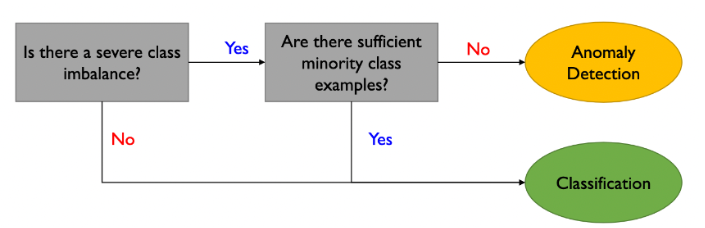
- 요약하면 데이터의 불균형이 심하며 불량 데이터의 수가 충분하지 않다면 anomaly detection을 사용하는게 바람직하며, 그 외에 경우에는 데이터 전처리를 해서라도 데이터 불균형을 해소한 후에 classification을 사용하는게 좋은 성능을 보여준다고 합니다.

- A, B 모두 데이터 불균형이 심하지만 B의 경우 불량 데이터의 절대적인 수가 많이 부족하기 때문에 이런 경우는 anomaly detection을 사용하는 것이 바람직합니다.
- Outlier 에도 3가지 종류가 존재합니다.
- Global Outlier: 일반적으로 저희가 인지하는 outlier로 누가봐도 명백히 이상한 outlier를 의미힙니다. 3가지 중에서 가장 판별하기 쉽습니다.
- Contextual Outlier: 상황/조건에 따라 이상치 여부가 달라지는 경우입니다. 예를 들어 외부기온을 측정하는 경우, 한국에서는 20도가 정상적인 온도지만 북극에서는 20도가 비정상적인 데이터가 됩니다.
- Collective Outlier: 데이터의 집합이 이상치가 되는 경우입니다. 3가지 중 가장 까다로운 경우로 데이터 공간에서 다수의 군집 속에 속하더라도 지나치게 한 지점에 모인다는 이유로 outlier가 되는 경우가 존재합니다.
- Anomaly Detection을 수행하려면 몇 가지 주의사항이 존재합니다.
- 모델과 outlier를 적절히 설정해야한다.
- 양질 / 불량 데이터들간의 경계를 설정하는 것은 쉬운 일이 아니기 때문에 적절한 모델과 경계를 설정하는 것이 매우 중요합니다.
- 목적/분야에 맞는 detection을 해야한다
- 의료분야에서는 작은 이상치라도 그 의미가 클 수 있습니다. 반면에 마케팅 분야에서는 보다 큰 변동까지도 수용이 가능할 수 있습니다. 따라서 목적/분야에 맞게 탐지를 하는 것이 중요합니다.
- 해석이 가능해야한다.
- 모델에 의해 outlier로 판단된 데이터가 왜 그런 결과가 나왔는지 해석이 가능해야 합니다.
- 모델과 outlier를 적절히 설정해야한다.
방법
Anomaly detection
- Density-based Methods
- Gaussian Density Estimation
- 데이터가 가우시안 분포에서 발생했다고 가정하여 정상 데이터들의 평균, 분산을 계산해 그 범위에서 벗어나는 데이터들을 불량 데이터로 판단하는 방법
- Mixture of Gaussian Densitiy Estimation
- 1번 방법과 동일하지만 데이터들의 분포가 다수의 가우시안 분포 결합에서 발생했다고 가정하는 방법
- Kernel Density Estimation
- 데이터가 특정 분포에서 발생했다고 가정하는 것이 아니며 데이터의 개수가 충분하다면 특정 데이터의 분포를 단순히 카운팅하는 방법으로 근사가 가능하다는 이론. 대표적인 방법이 Parzen window density estimator 입니다.
- Local Outlier Factor
- 메인 집합이 아닌 작은 집합들에서 발생할 수 있는 local outlier의 abnormal score을 명백한 outlier 보다도 더 크게 측정할 수 있도록 고안된 방법
- Gaussian Density Estimation
- Distance-based Methods
- K-nearest Neighbor-based Anomaly Detection
- 강의를 진행하신 강필성 교수님이 착안해낸 방법으로 단순히 군집으로 abnormal을 감지하는 것은 한계점이 있다는 점에서 출발한 이론입니다.
- 군집을 이루는 데이터들로 형성되는 polygon 내부에 감지하고자 하는 데이터가 포함되는지 여부까지 고려해서 abnormal을 판단하는 알고리즘입니다.
- K-means clustering based Anomaly Detection
- 단순하게 설명하면 어떤 군집과도 거리가 가깝지 않다면 abnormal로 판단하겠다는 이론입니다.
- PCA-based Anomaly Detection
- PCA 기반으로 주어진 데이터를 축약시킨후에 다시 복원시켰을때 본래의 데이터와 차이가 큰 데이터는 abnormal로 판단하는 방법입니다.
- 설명에 따르면 abnormal 데이터의 경우는 그 패턴이 제대로 파악되지 않았기 때문에 복원했을경우 기존 데이터와 거리가 멀어진다는 이론입니다.
- K-nearest Neighbor-based Anomaly Detection
- Model-based Methods
- Auto-Encoder
- 데이터를 latent space로 투영한 후에 다시 복원시켜서 차이가 큰 데이터는 abnormal 로 판단하는 방법
- 1-SVM
- SVDD
- Auto-Encoder
- Isolation Forest
'4. 논문리뷰 > Time-series Anomaly detection' 카테고리의 다른 글
| Deep One-Class Classification (0) | 2022.10.31 |
|---|---|
| ANOMALY TRANSFORMER: TIME SERIES ANOMALYDETECTION WITH ASSOCIATION DISCREPANCY (0) | 2022.10.20 |
| TAD 벤치마크 데이터셋 (0) | 2022.10.20 |
| DAD(Deep Anomaly Detection) 서베이 (0) | 2022.10.20 |