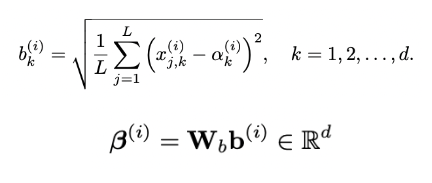1. Introduction
논문 링크 : http://proceedings.mlr.press/v80/ruff18a/ruff18a.pdf
해당 논문은 Anomaly Detection 분야에서 베이스라인으로 자리잡은 DeepSVDD 라는 모델이다. 근간이 되는 이론은 SVM(정확히는 OC-SVM) 과 매우 유사하다. OC-SVM latent space 에서 정상 / 비정상 클래스를 구분할 수 있는 가상의 hyperplane 을 찾아내는 문제였다면, SVDD 는 어떤 중심점을 기준으로 가상의 원을 찾아내겠다는 이론이다. 그리고 이를 딥러닝에게 맡기겠다는 것이 DeepSVDD 이다. OC-SVM 도 좋은 알고리즘이지만 고차원 데이터에서는 잘 작동하지 않기 때문에 이러한 방법이 제안되었다.
2. Background
2.1 Kernel-based One-Class Classification
SVM 이론은 깊숙히 들어가면 굉장히 어려운 이론이기 때문에 공식으로만 이해한다면


첫번째 term 은 일종의 보정(regularizer)이라고 생각하면 된다. 두번째 term은 원점과 hyperplane 까지의 거리로 목적함수에 의하면 최대한 값이 커지게 하는 것이 목적이다. OC-SVM은 무조건 원점을 기준으로 정상 / 비정상 클래스를 나누기 때문에 원점으로부터 hyperplane을 최대한 멀어지게 하는 것이 바람직하다는 말이다. 마지막 term 은 매핑된 데이터들과 hyperplane 까지의 거리를 의미하며 $v$ 값은 trade-off 값이다. 해당 term 은 논문에서 slack variables 라고 부르는데 해당 변수를 통해 soft / hard boundary 를 조절할 수 있다. 위의 목적함수에 따라 최대한 많은 데이터 포인트가 hyperplane 바깥에 위치하게 된다.
2.2 SVDD
SVDD 도 마찬가지로 공식만 살펴본다면


R 은 경계면까지의 반지름을 의미하며 마찬가지로 soft / hard boundary 를 결정하는 변수도 있다.
3. Main
3.1 Deep SVDD
원리는 위에서 설명한 SVDD 와 동일하다. 다만 OC-SVM, SVDD 는 원하는 hyperplace, sphere 를 계산하기 위해서 복잡한 과정(라그랑주)을 거쳐야한다. 이것을 딥러닝으로 해결해보자는 접근법이 Deep SVDD 이다. Deep SVDD 의 목적함수는 아래와 같다.

마찬가지로 반지름은 최대한 줄이면서, 동시에 원 밖에 있는 데이터들도 경계면에 최대한 근접하게 하는 것이 목적이다. 거기에 약간의 regularization 을 추가하면 최종목적함수가 된다. 논문에서 제시한 기본 모델은 위의 목적함수에 따라 학습을 진행하며 이를 SOFT-BOUND. Deep SVDD 라고 명명했다. 여기에 추가로 간단한 버전의 모델도 제시했으며, 해당 모델의 목적함수는 아래와 같다. (결과적으로는 후자모델이 더 성능이 좋았다.)

원 밖의 데이터들의 경계면까지의 거리는 더 이상 고려하지 않고, 그냥 모든 데이터에 대해서 중심점까지의 거리를 최대한 줄여주겠다는 뜻이 된다. 단순히 모든 데이터들의 평균거리를 고려함으로서 SOFT-BOUND. Deep SVDD 와 비슷한 효과를 기대한다고 한다. 다만 이를 위해서 학습 데이터의 상당수는 한 개의 클래스에서 추출되었다고 가정했다.
3.2 Properties of Deep SVDD
저자는 Deep SVDD 의 학습이 제대로 이루어지려면 4가지 특성을 충족해야 한다고 설명했다.
3.1.1 All-zero-weights solution
명확히 이해한 것인지는 모르겠지만 간략히 설명한다면 중심점이 제대로 설정이 되지 않는다면 뉴럴넷의 모든 weight이 0이 되는 결과를 얻을 수 있다는 것이다. 모든 값이 0인 weight 를 $W_{0}$ 라고 한다면 이 뉴럴넷은 모든 입력을 한 점 $c_{0}$으로 매핑할 것이다. 그런데 만약 우리가 최적화할 중심 $c$를 $c_{0}$ 로 설정한다면 뉴럴넷은 진짜로 $W_{0}$ 로 학습이 될 것이다. 따라서 적절한 중심점을 선택하는 것이 매우 중요하며 논문에서는 실험결과 학습 데이터 일부를 forward 시킨 다음에 평균을 구하는 것이 괜찮다고 한다.
3.1.2 Bias terms
이것도 이전 경우와 약간 비슷한 경우인데, 특정 layer 에서 만약 weight 값들이 모두 0이라면 어떤 입력이든 결국 bias term 에 의해 다음 layer 로의 input 이 결정된다. 이럴 경우 뉴럴넷이 그냥 어떤 입력이든 $c$로 매핑하는 bias 를 학습할 가능성이 있다는 것이다. 따라서 Deep SVDD 에서는 모든 레이어에서 bias 를 사용하지 않았다.
3.1.3 Bounded activation functions
해당 특성은 bouned activation function 을 사용할 경우 발생할 수 있는 특성에 대한 설명이다. 만약 우리가 가진 데이터 중에서 특정 차원의 데이터가 모두 양수라고 가정해보자. 그런데 이때 bounded activation function(sigmoid, tanh) 를 사용하게 된다면 한 쪽 방향으로만 계속 이동하게 될테고 결국 포화상태에 이르게 된다. 즉, 모든 입력에 대해서 해당 dimension 의 weight 는 그냥 무작정 크게 학습이 된다는 것이다. 그렇게 학습을 해도 bounded 이기 때문에 최대값은 커질 수 없기 때문이다. 그렇게 된다면 이후에는 또 다시 bias term 들에 의해 입력에 상관없이 똑같은 output을 내는 네트워크가 완성될 가능성이 생기게 된다. 따라서 그냥 ReLU 를 쓰라는 것이다.
3.1.4 ν-property
이것은 SOFT-BOUND 버전 모델에 적용되는 사항으로 일단은 넘어가도록 하겠다.
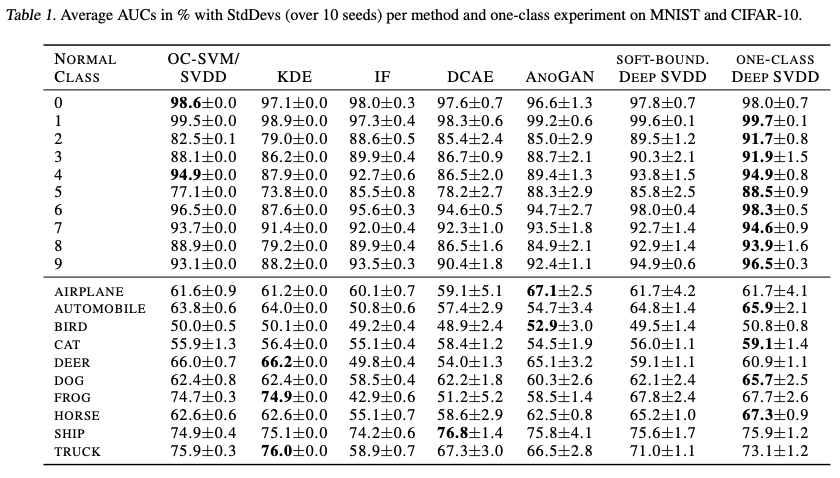
4. Experiment
'4. 논문리뷰 > Time-series Anomaly detection' 카테고리의 다른 글
| ANOMALY TRANSFORMER: TIME SERIES ANOMALYDETECTION WITH ASSOCIATION DISCREPANCY (0) | 2022.10.20 |
|---|---|
| TAD 벤치마크 데이터셋 (0) | 2022.10.20 |
| DAD(Deep Anomaly Detection) 서베이 (0) | 2022.10.20 |
| Anomaly Detection 개념 정리 (0) | 2022.10.20 |